
Machine learning initiatives often fail not because of weak models, but because of poor operationalization. Enterprises invest heavily in experimentation and model development, yet struggle when it comes to deployment, monitoring, governance, and scaling. This gap between experimentation and production is precisely where MLOps (Machine Learning Operations) becomes essential.
In this guide, we explore the MLOps lifecycle, architectural components, and best practices required to build scalable, secure, and production-ready AI systems.
What is MLOps?
MLOps is a structured set of practices that combines Machine Learning, DevOps, and Data Engineering to automate and streamline the entire ML lifecycle—from development to deployment and continuous monitoring. It brings engineering discipline to AI systems, ensuring they are reliable, reproducible, and scalable.
At its core, MLOps enables faster model deployment, reproducibility across environments, continuous monitoring of production performance, governance and compliance enforcement, and scalable infrastructure management. For enterprises investing in AI platforms, MLOps is no longer optional—it is foundational to operational success.
The Complete MLOps Lifecycle
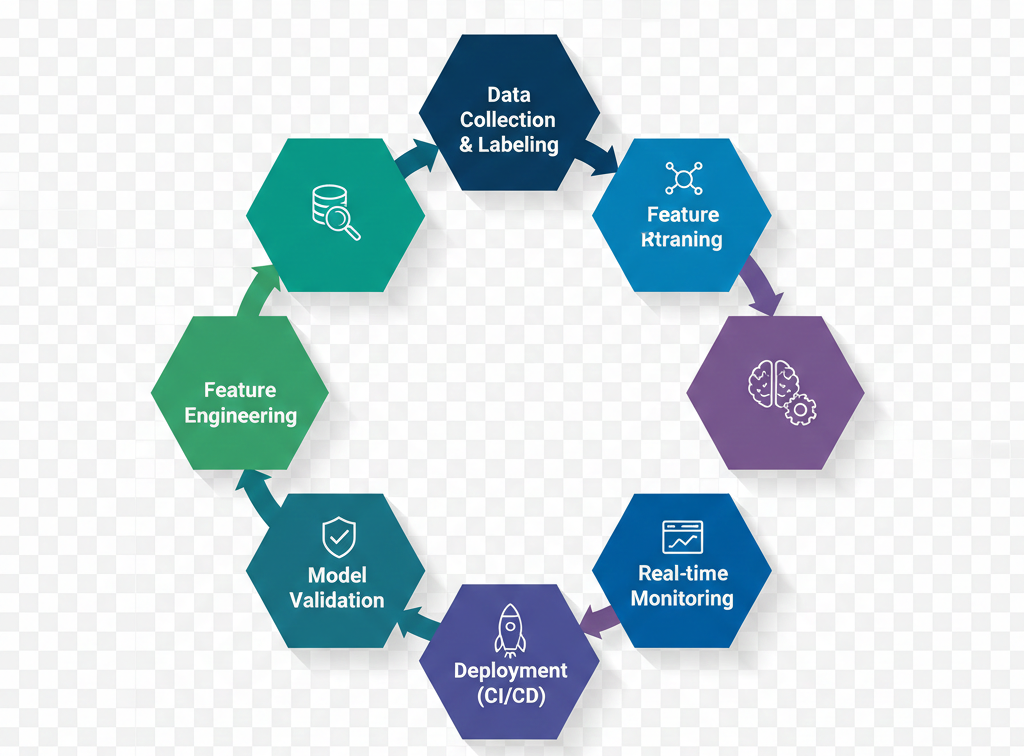
The MLOps lifecycle ensures that AI systems move seamlessly from data ingestion to long-term optimization.
1. Data Collection & Validation
The lifecycle begins with gathering structured and unstructured data from multiple sources. Data quality validation is critical at this stage, including anomaly detection and drift analysis. Compliance requirements such as HIPAA, GDPR, or SOC 2 must also be addressed to ensure secure and lawful data handling.
2. Data Preparation & Feature Engineering
Raw data must be cleaned, normalized, and transformed into meaningful features. Automating feature pipelines reduces manual errors and improves consistency. Versioning datasets ensures traceability and reproducibility across experiments.
3. Model Development
During development, teams perform experiment tracking, hyperparameter tuning, and iterative optimization. Model versioning becomes essential to compare performance across iterations and maintain transparency.
4. Model Validation & Testing
Before deployment, models undergo structured validation processes. This includes accuracy evaluation, bias and fairness checks, stress testing, and performance benchmarking to ensure readiness for real-world conditions.
5. Deployment
Deployment integrates CI/CD pipelines tailored for ML workflows. Containerization technologies such as Docker and orchestration platforms like Kubernetes enable scalable, API-based model serving. Automated pipelines reduce human error and accelerate release cycles.
6. Monitoring & Observability
Once deployed, models require continuous monitoring. This includes performance tracking, data drift detection, latency measurement, and alerting mechanisms for model decay. Observability ensures production systems remain aligned with business objectives.
7. Continuous Improvement
Feedback loops capture real-world outcomes and feed them back into retraining pipelines. Governance audits ensure compliance and risk management. Continuous improvement transforms AI systems into adaptive assets rather than static deployments.
Together, this lifecycle ensures AI systems remain reliable, secure, and production-ready over time.
MLOps Architecture Overview
A robust MLOps architecture typically consists of several integrated layers. The data pipeline layer manages ingestion, transformation, and storage. Experimentation and tracking tools support model development and comparison. A centralized model registry maintains approved versions ready for deployment.
CI/CD automation pipelines streamline testing and release processes, while monitoring and alerting systems track production health. Finally, a governance and compliance layer enforces security controls, auditability, and regulatory alignment.
This layered architecture ensures that experimentation, deployment, and monitoring operate as a unified system rather than disconnected workflows.
MLOps Best Practices for Enterprises
Scalable AI systems require disciplined implementation. One of the most critical practices is versioning everything—code, data, models, and configurations. Reproducibility strengthens trust and simplifies compliance audits.
Automation is equally essential. CI/CD for ML pipelines, automated testing, and scheduled retraining reduce operational risk and accelerate deployment cycles. Continuous monitoring must track not only model accuracy but also data drift, latency, and business KPIs to prevent silent degradation.
Governance and security should be embedded from the beginning. Role-based access control, audit trails, explainability tools, and secure model endpoints protect enterprise assets. Infrastructure as Code (IaC), using tools such as Terraform, standardizes deployments and improves consistency across environments.
Finally, systems must be designed for scalability. Containerized deployments, auto-scaling capabilities, and cost-optimized inference strategies ensure that AI platforms can grow without compromising efficiency.
Why MLOps is Critical for Enterprise AI
Without MLOps, models frequently fail in production, operational costs escalate, compliance risks increase, and stakeholder trust declines. Experimental success does not translate into business value without operational discipline.
With MLOps in place, deployment cycles can shrink significantly, monitoring improves model reliability, and AI initiatives scale confidently across departments. Enterprise AI success depends as much on operational excellence as it does on model innovation.
Common MLOps Challenges
Organizations often face recurring challenges when operationalizing AI. Data drift can degrade model performance if not detected early. Manual deployment processes increase error rates and delay releases. Poor monitoring leads to undetected failures in production environments. Compliance gaps introduce legal and financial risks, particularly in regulated industries. Additionally, lack of collaboration between data scientists, engineers, and operations teams slows AI adoption.
Addressing these challenges requires structured governance, automation, and cross-functional alignment.
Conclusion
MLOps transforms machine learning from isolated experiments into scalable, enterprise-grade systems. By automating deployment, enforcing governance, enabling continuous monitoring, and embedding reproducibility into workflows, organizations can reduce operational risk and maximize AI return on investment.
A strong MLOps foundation ensures that AI systems remain reliable, compliant, and adaptable—making it essential for long-term enterprise AI success.
Ready to future-proof your enterprise with AI?
- Connect us – https://internetsoft.com/
- Call or Whatsapp us – +1 305-735-9875
ABOUT THE AUTHOR

Abhishek Bhosale
COO, Internet Soft
Abhishek is a dynamic Chief Operations Officer with a proven track record of optimizing business processes and driving operational excellence. With a passion for strategic planning and a keen eye for efficiency, Abhishek has successfully led teams to deliver exceptional results in AI, ML, core Banking and Blockchain projects. His expertise lies in streamlining operations and fostering innovation for sustainable growth





")
")

